Publications
Ordered in reversed chronological order.
2024
-
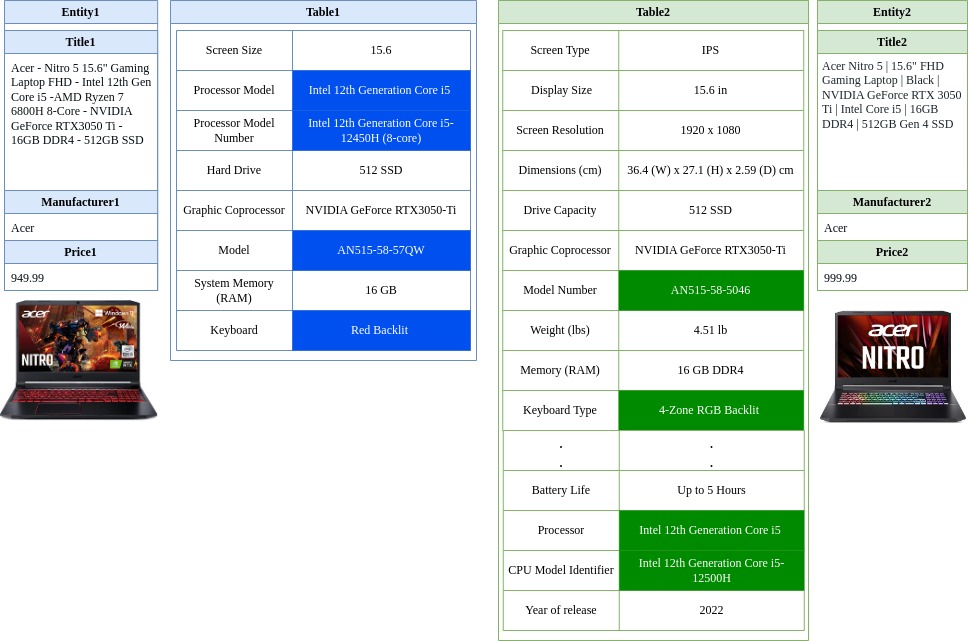 TATTOO: Product Entity Matching as a Topology Construction [submitted]Ali Naeimabadi, Mir Tafseer Nayeem, and Davood RafieiIn WSDM, Mar 2024
TATTOO: Product Entity Matching as a Topology Construction [submitted]Ali Naeimabadi, Mir Tafseer Nayeem, and Davood RafieiIn WSDM, Mar 2024The domain of Product Entity Matching (PEM)— a subfield of record linkage that focuses on linking records referring to the same product— presents a formidable challenge for various entity matching models. Notably, transformer-based models have demonstrated exceptional performance across numerous datasets; however, their efficacy drops significantly when applied to PEM datasets. This research endeavor is centered upon an investigation of PEM within the common setting wherein information is distributed across both textual and tabular formats. The present study underscores that the incorporation of detailed product tables holds the potential to enhance existing PEM datasets by serving as connections that link associated entities. To facilitate the establishment of such connections among product entities, we reformulate the problem of PEM as a topology construction and introduce two PEM datasets enriched with product detail tables. Our high-performance PEM model named TATTOO relies on the capabilities of pre-trained language models and employs our innovative serialization technique to encode product-specific tabular data. Our proposed model utilizes two independent attribute ranking modules to improve data efficiency and disambiguate hard negative examples. Our experiments on both existing benchmark datasets and our proposed datasets demonstrate significant improvements compared to state-of-the-art methods, including large language models, in zero-shot and few-shot settings. The proposed model also exhibits greater robustness in the face of domain shifts and limited training data compared to well-known benchmark models.
2023
-
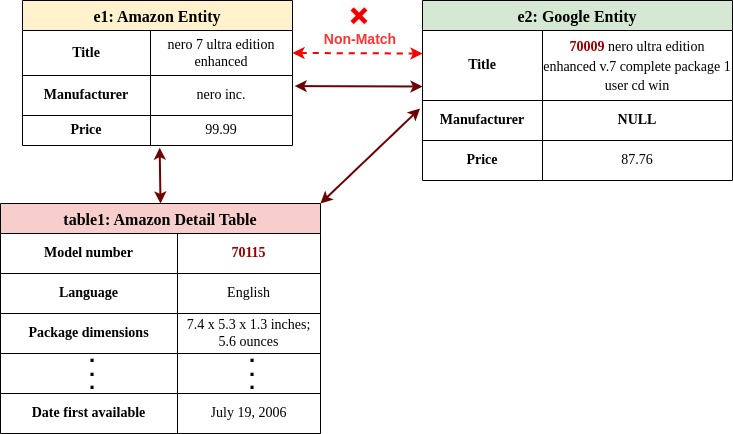 Product Entity Matching via Tabular DataAli Naeimabadi, Mir Tafseer Nayeem, and Davood RafieiIn CIKM, Oct 2023
Product Entity Matching via Tabular DataAli Naeimabadi, Mir Tafseer Nayeem, and Davood RafieiIn CIKM, Oct 2023Product Entity Matching (PEM) –a subfield of record linkage that focuses on linking records that refer to the same product– is a challenging task for many entity matching models. For example, recent transformer models report a near-perfect performance score on many datasets while their performance is the lowest on PEM datasets. In this paper, we study PEM under the common setting where the information is spread over text and tables. We show that adding tables can enrich the existing PEM datasets and those tables can act as a bridge between the entities being matched. We also propose TATEM, an effective solution that leverages Pre-trained Language Models (PLMs) with a novel serialization technique to encode tabular product data and an attribute ranking module to make our model more data-efficient. Our experiments on both current benchmark datasets and our proposed datasets show significant improvements compared to state-of-the-art methods, including Large Language Models (LLMs) in zero-shot and few-shot settings.
2022
-
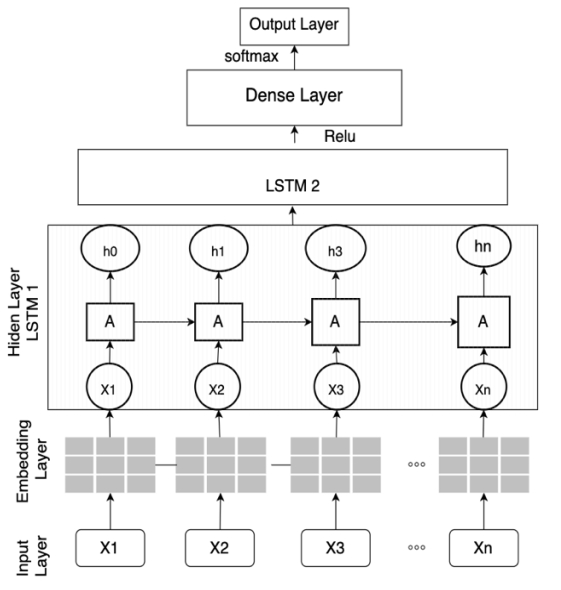 The Effect of Fine-tuned Word Embedding Techniques on the Accuracy of Automated Essay Scoring Systems Using Neural NetworksTehereh Firoozi, Okan Bulut, carrie Demmans Epp, Ali Naeimabadi, and Denilson BarbosaIn NCME, Apr 2022
The Effect of Fine-tuned Word Embedding Techniques on the Accuracy of Automated Essay Scoring Systems Using Neural NetworksTehereh Firoozi, Okan Bulut, carrie Demmans Epp, Ali Naeimabadi, and Denilson BarbosaIn NCME, Apr 2022Automated Essay Scoring (AES) using neural networks has helped increase the accuracy and efficiency of scoring students’ written tasks. Generally, the improved accuracy of neural network approaches has been attributed to the use of modern word embedding techniques. However, which word embedding techniques produce higher accuracy in AES systems with neural networks is still unclear. In addition, the importance of fine-tuned word embedding techniques on the accuracy of the AES systems is not justified yet. This study investigates the effect of fine-tuned modern word embedding techniques, including pretrained GloVe and Word2Vec, on the accuracy of a deep learning AES model using a Long-Short Term Memory (LSTM) network. The dataset used in this study consisted of 12,978 essays introduced in the 2012 Automated Scoring Assessment Prize (ASAP) competition. Results show that fine-tuned word embedding techniques could significantly improve the accuracy of the AES (QWK= 0.79) compared with the baseline model without pretrained embeddings (QWK = 0.73). Moreover, when used in AES, the pre-trained GloVe word embedding (QWK= 0.79) outperformed Word2Vec (QWK = 0.77). The results of this study can guide future AES studies in selecting more appropriate word representations and how to fine-tune the word embedding techniques for scoring-related tasks.